





Unsere Produkte
Die Lösungen von OneSpan für digitale Identität und Betrugsbekämpfung helfen unseren Kunden, sichere digitale Prozesse bereitzustellen

Identitätsverifizierung und Authentisierung

Virtual Room

Elektronische Signatur

Intelligente adaptive Authentifizierung

Sicherheit für Mobile Apps
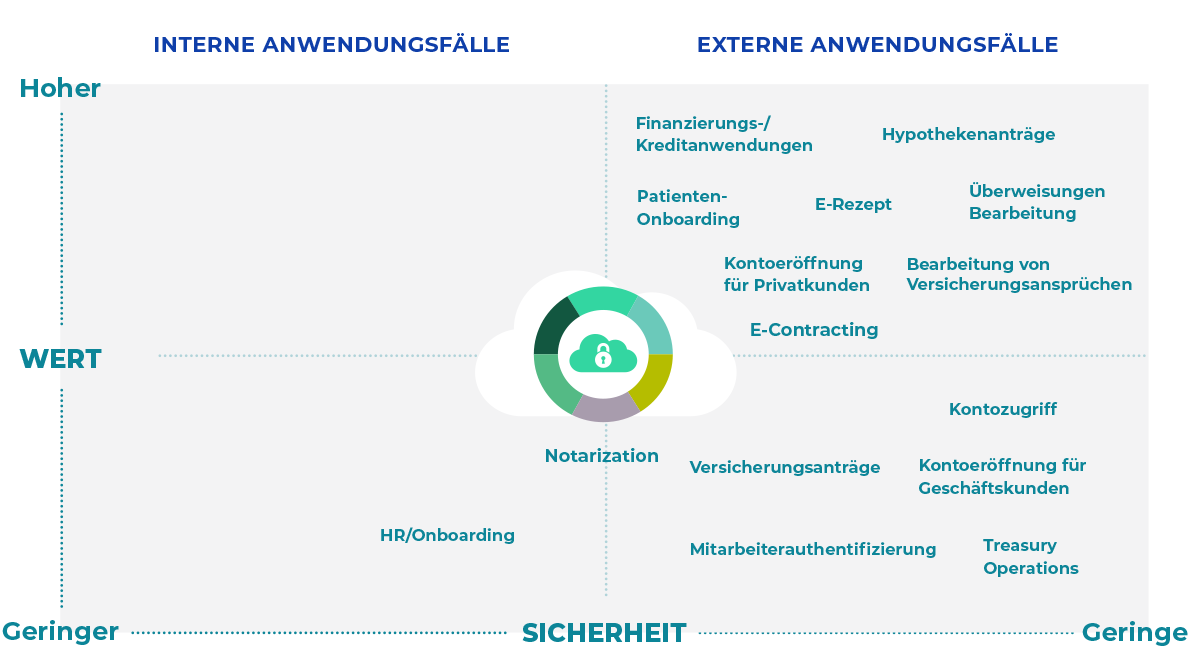
Fallbeispiele
Lösen Sie geschäftliche Herausforderungen und erreichen Sie transformative Ergebnisse







Unsere geschätzten Kunden
Mehr als die Hälfte der 100 weltweit führenden Banken und zahlreiche internationale Unternehmen vertrauen auf OneSpan, um die Kundenerfahrung zu verbessern und ein Höchstmaß an Sicherheit zu gewährleisten.





What customers are saying
I love the fact that [OneSpan Sign] allows our company to label pages and processes with our proprietary mark, not the electronic signature mark.

Legen Sie noch heute los!
Tools und Ressourcen, die Sie für einen sicheren Betrieb startklar machen



Was ist neu bei OneSpan

Eine Nachricht von unserem CEO
Deep Fakes stellen eine neue Realität dar. Wie können wir Vertrauen und Integrität zurückbringen?

Abwehr von Social Engineering Angriffen
Banken und Finanzinstitute passen sich schnell an die Bedürfnisse ihrer Kunden an. Entdecken Sie die wichtigsten zu digitalisierenden Bankprozesse.

Humanressourcen
Europäische HR-Plattform Akyla verschafft sich mit OneSpan einen Wettbewerbsvorteil.

Übersicht über OneSpan Sign mit ID-Verifizierung
Sehen Sie sich an, wie mit der ID-Prüfung in OneSpan Sign die Identität eines Unterzeichners validiert werden kann.

NewB implementiert Sicherheitslösun
Die Application-Shielding Technologie schützt die Bankanwendung von NewB.

Passwortlose Authentifizierung
Frost & Sullivan | 2022 Product Leader: Continuous Passwordless Authentication.
1 G2 Crowd Grid Report for E-Signature - Spring 2022
2 Gartner, Market Guide to Electronic Signature, July 6, 2022 , James Hoover, Tricia Phillips
https://www.onespan.com/resources/gartner-market-guide-electronic-signature
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner's research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed, or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark, and PEER INSIGHTS is a trademark, of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved. Gartner Peer Insights content consists of the opinions of individual end users based on their own experiences with the vendors listed on the platform, should not be construed as statements of fact, nor do they represent the views of Gartner or its affiliates. Gartner does not endorse any vendor, product or service depicted in this content nor makes any warranties, expressed or implied, with respect to this content, about its accuracy or completeness, including any warranties of merchantability or fitness for a particular purpose.
The information contained in this page is for information purposes only. OneSpan does not accept liability for the contents of these materials or for third parties materials mentioned in this page.